
[뉴스비전e 정윤수 기자] 법률시장에 인공지능(AI) 기술이 속속 도입되고 있다.
가트너는 오는 2022년까지 스마트 머신과 로봇이 의료, 법률, IT 분야의 고학력 전문직 업무를 대체할 것이라고 예측했다.
AI기술은 법률 분야에서 아직 서포터 역할에 그치고 있지만 장기적 관점에서 법률 전문가의 고유 영역을 파고들것으로 전망되고 있다.
미국에서는 2016년 뉴욕에 위치한 대형 로펌 베이커앤드호스테틀러가 IBM 왓슨 API를 적용한 AI 변호사 '로스(ROSS)'를 도입했다. 240년간 수집된 판례와 관련 법 조항을 단 몇 초 만에 검토하는 능력을 갖췄다.
초당 10억장에 달하는 법률문서를 분석해 관련 법 조항과 판례를 검색해 사람과 대화하듯 자연어로 24시간 상담을 해준다. 현재 미국 내 12개 이상의 법무법인에서 로스가 일하고 있으며, 유럽에서도 로스의 도입을 검토 중이다.
미국 법률자문회사 로스인텔리전스는 인공지능 기술을 활용해 ‘대화체’로 질문하면 연관된 판례 등을 제공하는 서비스를 2016년 개발했다.
국내에서도 법률 검색 특화 인공지능 개발과 도입이 활발히 이루어지고 있다.
◆정부 및 민간...AI로 법률서비스 확장
정부는 지난 달 보유한 각종 법령과 판례정보를 검색해 법률상담을 제공하는 인공지능 시스템을 도입한다고 밝힌 바 있다. 법제처는 지능형 법률정보 검색과 대화형 법률상담, 결과예측 등이 가능한 인공지능을 만들어 4차 산업혁명에 대응하겠다는 방침이다.
법제처는 올해부터 관련 법령정보를 토대로 AI를 시범 구축하고 민사·형사 소송 등으로 적용 범위를 확대하겠다는 계획이다.
대법원은 개인회생파산, 전자소송 등에 AI 도입을 추진하고 있다. 대법원은 올해 AI 기반의 지능형 개인회생파산 시스템 구축전략을 수립하는 한편 지능형 차세대 전자소송시스템 구축사업을 추진한다.
정부 뿐만 아니라 민간 기업에서도 개발과 도입이 활발이 이루어지고 있다.
율촌, 태평양 등 대형 로펌 출신 변호사들이 창업한 '헬프미'는 AI를 활용해 비용을 대폭 낮췄다. 이 회사는 IT개발자들을 고용해 2016년 지급명령 자동화 서비스를 시작으로 법인등기, 상속문제 등 서비스를 속속 개발하고 있다.
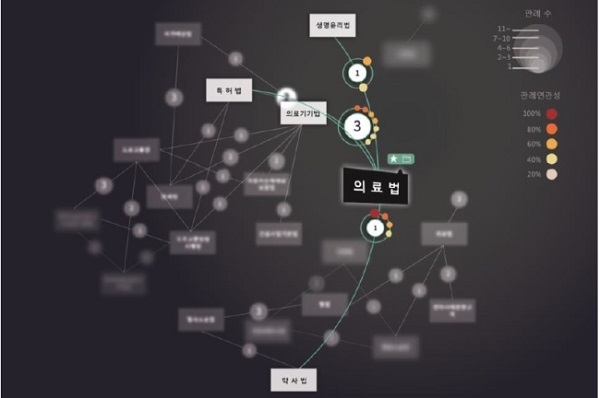
변호사와 AI 전문가들로 구성된 인텔리콘법률사무소도 지난해 AI 법률정보시스템 '아이리스(i-LIS)'를 개발해 서비스하고 있다.
벤처 코어닷투데이는 일반인도 법률을 쉽게 검색할 수 있도록 돕는 법률 특화 검색엔진 ‘로우봇(LAWBOT)’을 개발했다.
로우봇은 ‘텍스트 마이닝(Text Mining)’과 ‘딥 러닝(Deep Learning)’이라는 데이터 처리 기술을 통해 단어가 아닌 의미 중심으로 법률 검색이 가능하다. 그 결과, 검색의 정확성을 높이고, 더 많은 검색 결과를 제공한다.
텍스트 마이닝은 문장의 규칙이나 패턴을 분석을 통해 의미 있는 정보를 추출하는 기술로서 문서 내 특정 단어의 출현 빈도 등을 파악해 반복되는 단어들의 관계를 분석한다. 텍스트 마이닝으로 분석된 정보는 다시 딥 러닝 기술을 통해 의미 별로 분류된다. 딥 러닝은 인공지능이 사람의 뇌처럼 데이터를 반복 학습 후 데이터를 분류하는 기술이다.
사용자가 로우봇을 이용할 시 판례문의 작성 원칙인 ‘주어’, ‘일시’, ‘상대방’, ‘목적물’, ‘행위’를 입력하면 관련 판례와 법령이 검색된다. 사용자는 해당 판례가 참고한 법률과 판례까지 제공받아 해당 건의 판결을 예측할 수 있다.
코어닷투데이는 법률 데이터 구축과 해석의 전문성을 높이기 위해 변호사를 팀원으로 고용했다. 법령과 판례의 구조 및 정보를 인공지능이 반복 학습할 수 있도록 데이터베이스를 구축하는 것이 변호사의 역할이다. 기술 개발자가 할 수 없는 법률 연구를 변호사가 직접 수행해 법률 구조 분석의 정확성을 확보했다. 현재까지 코어닷투데이가 분석한 법령과 판례의 수는 약 55만 건이다.
◆어떤 기술이 사용되나
기존 법률 검색 서비스는 단어 중심으로 해당 단어가 문서에 정확히 포함되어야지만 검색이 가능해 정확도가 떨어진다.
AI는 법률 데이터를 검색, 분석하고 이를 시각화하는 플랫폼으로 쉽게 법률 정보를 검색하고 이용할 수 있도록 돕는다.
근간이 되는 알고리즘은 텍스트 마이닝과 딥러닝 기술이다.
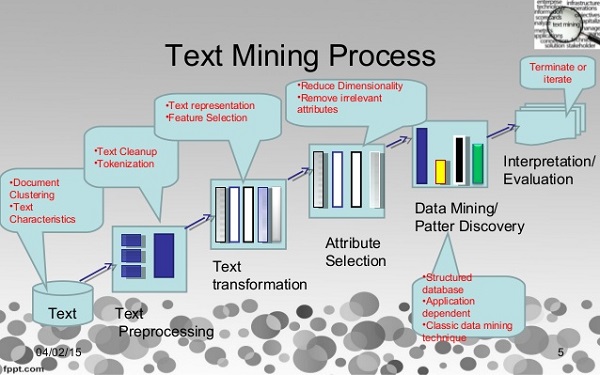
텍스트 마이닝이란 텍스트에서 얻어지는 정보를 이해하기 위한 기술로, 텍스트에 나타나는 단어를 분해하고 특정 단어의 출현빈도, 동시출현 빈도 등을 파악해서 단어들의 관계를 분석하는 것을 말한다.
이 때 한국어의 형태소 분석이 필요한데, 형태소 분석이란 문장에서 명사, 동사, 형용사, 부사 등 최소 단위인 형태소를 추출하는 것을 말한다.
이러한 텍스트 마이닝을 거친 정보를 가지고 법률 텍스트 데이터의 의미 파악을 시도하며, 이 때 텍스트의 의미를 파악하기 위해서 분산표현(Distributed representation) 방법을 사용한다.
분산 표현 방법이란 쉽게 말해 공간 상에서 비슷한 의미를 가진 단어들은 학습을 할수록 가까워지도록 하는 것을 말한다.
예를 들어, 3차원의 공간 상에 단어 ‘신발’, ‘샌달’, ‘슈즈’ 세 개가 있다. 이 단어들은 처음에는 어떤 관계 즉, 의미가 있는지 파악할 수 없다. 하지만 기계학습을 통해 이 단어들의 위치를 수정해 가며, 결국 의미적으로 유사한 단어들은 밀집된 공간에 모이게 된다. 이를 통해 AI는 단어의 의미를 파악할 수 있게 되는 것이다.
이러한 기술에는 “비슷한 문맥을 가진 단어는 비슷한 의미를 갖는다.”는 가정이 깔려 있다.
이러한 결과로 단어의 의미를 학습하게 되며, 의미 학습은 단어를 넘어 사건, 판례, 법령 등으로 확장시켜 학습하고 있어 결과물이 반영돼 시간이 지날수록 더 정확한 검색결과를 제공하는 법률 비서로 진화하는 것이다.